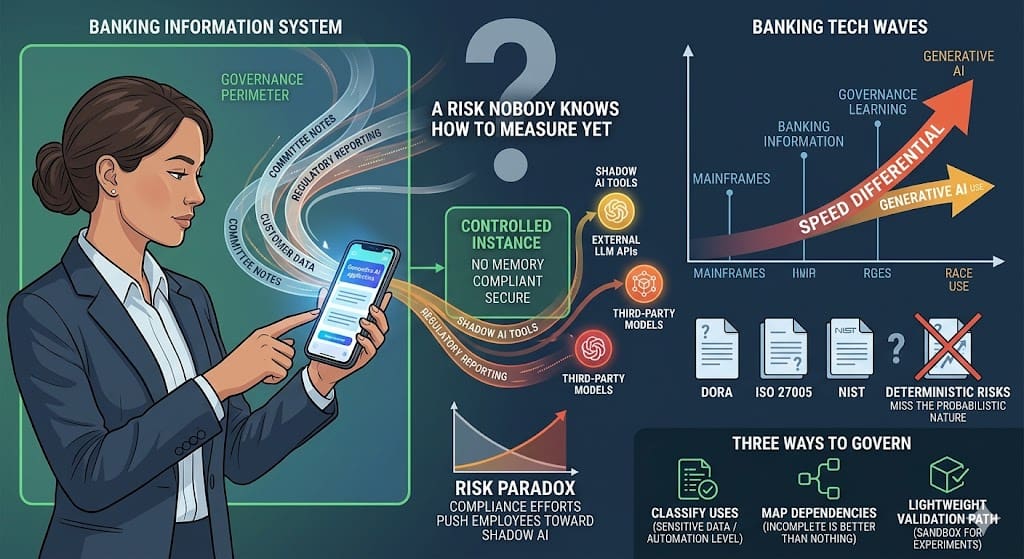
Picture the scene: your bank has just deployed a generative AI banking tool internally. Dedicated instance, controlled hosting, no memory between sessions. Compliant, secure, and frankly less capable than what they use at home in the evening. The next day, they are processing committee meeting notes on a public tool, from their personal phone, because it is faster. Nobody banned anything. Nobody approved anything either.
This scenario may not be your reality yet. It will be.
That is the real issue with generative AI in banking information systems today. Not the algorithms, not the performance benchmarks, not even the incoming regulation. It is the capillarity. And more precisely, a paradox that few organisations anticipated: compliance efforts sometimes produce exactly the behaviour they were designed to prevent. By offering a controlled but functionally stripped-down environment, organisations push employees toward shadow AI, where tools are more powerful, less constrained, and entirely outside the governance perimeter.
How banking has always struggled to govern new technology
Every major technology wave in banking cybersecurity has followed the same pattern. Mainframes first, then networks, then the web, then the cloud. Each time, the same sequence: usage emerges in business or IT teams, gains momentum before risk and security functions have built their doctrine, and governance catches the moving train, sometimes years late.
This is not a criticism. It is a structural reality. Organisations cannot finely anticipate the risks of technologies they do not yet fully understand. And business teams do not wait for a framework to be published before finding more efficient ways to work.
The difference this time is speed and opacity. A cloud deployment in a large bank took years. A tool built on a large language model can be integrated into a workflow in days, by any team with access to an API.
And unlike the cloud, whose perimeter can be mapped fairly well once you commit to it, the dependencies around language models are much harder to trace. Your tool calls an LLM. That LLM may itself be built on several third-party models. Data passing through it could be used for fine-tuning somewhere down the chain. Or not. You do not always know.
What DORA and ISO 27005 miss about generative AI banking risk
DORA, ISO 27005, the NIST Cybersecurity Framework: these texts were designed in a world where risks, however complex, remained relatively deterministic. A vulnerability has an attack vector. An incident has a root cause. An asset inventory tells you what you are exposing.
With LLMs, behaviour is not deterministic. The same prompt can produce different outputs depending on context, model version, parameters you do not control. Assessing the risk of a system built on an LLM does not look like assessing a conventional system. The usual criteria — availability, integrity, confidentiality — still apply, but they are not enough to capture risks like hallucinations in decision-making processes, or implicit context leakage.
DORA, in its article 28 on critical third-party providers, begins to grasp part of the problem by extending the supervision perimeter to suppliers. But an LLM provider is not a conventional IT supplier: the service it delivers is fundamentally probabilistic, and the way it processes incoming data is not always auditable in the traditional sense of the word.
This is not a criticism of the people who drafted these texts. It is simply that regulation, by nature, documents risks it has had time to observe and model. We are still in the observation phase.
Three ways to govern generative AI banking risks today
Faced with this uncertainty, the temptation is either to ban (ineffective, usage finds a way around) or to wait for regulators to publish their guidelines (too slow, deployment continues). There is a third path, less spectacular but more operational.
Start by classifying uses. Not all uses of generative AI in a banking organisation carry the same level of risk. Drafting an internal communication on a non-sensitive topic is not the same as using an LLM to analyse customer data or produce regulatory reporting elements. A simple classification grid, crossing the sensitivity of data processed against the level of automation of the output, makes it possible to distinguish what can move freely from what requires a stricter governance framework.
Map the dependencies, even imperfectly. You do not need an exhaustive map to start gaining visibility. Even an incomplete inventory of tools calling external LLM APIs — by team, by use case, by data type — is better than nothing. This map will be wrong at the start. It will improve. That is the principle.
Create a lightweight validation path for experiments. If the only route to using an AI tool runs through a six-month validation process, teams will work around it. A short circuit — a few clear criteria, a two-week review, an isolated sandbox — allows you to recover visibility on what is happening while still letting teams innovate. Governance by design, not governance by prohibition.
A question of pace
What strikes me, at the end of the day, is not the novelty of the problem. It is the speed differential between what organisations are capable of learning and the pace at which uses become entrenched.
In previous cycles, that differential existed too. But it left a little more time. Now, generative AI banking tools are embedded in critical workflows in days, while governance teams are still reading the first analytical reports published on the subject.
I do not think the answer is to move faster in governance — there are structural limits to that. I think the answer is to accept that risk will be imperfectly controlled for a while, and to build mechanisms that allow for rapid detection and correction rather than pretending to prevent everything exhaustively.
That is a fairly deep shift in posture for security teams whose role has long been to say no before things go wrong. But it is probably the only realistic posture in this context.
The real question is not whether your teams are already using LLMs in their daily work. They are. The question is whether you have any way of knowing.


0 Comments